首批成员单位!润和软件与润开鸿联袂加入开放原子开源基金会智能体开源工作组


发布时间:2025-06-11浏览次数:1278
江苏润和软件股份有限公司(以下简称“润和软件”)自主研发的StackRUNS异构分布式推理框架已在实际场景中取得显著成效,成功应用于大型园区多模态模型演练及高校满血版DeepSeek-MoE 671B的运行,有效推动了大模型技术的快速落地。
案例一:大型园区多模态模型演练
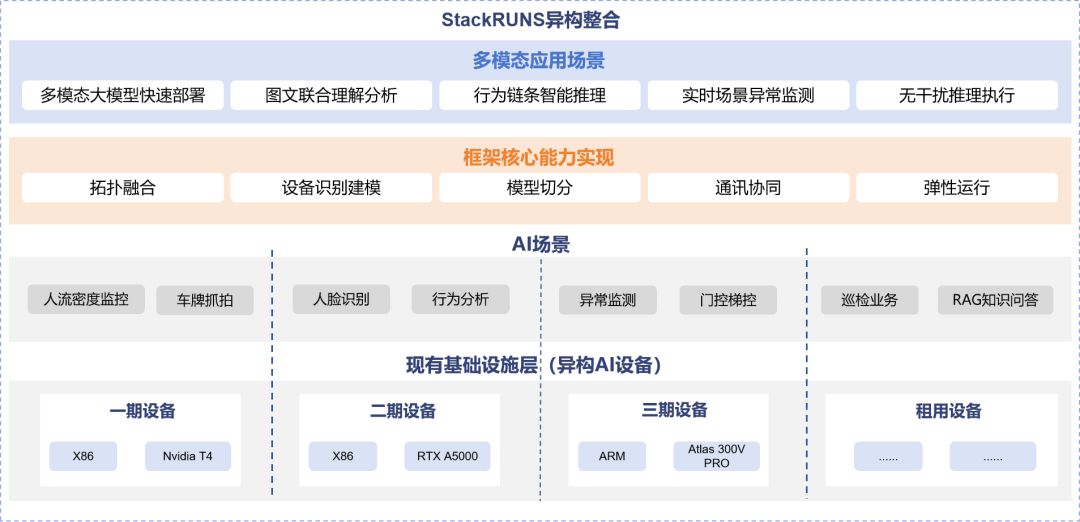
由于建设分期不同及承建单位多样,该智慧园区的AI基础设施呈现出高度异构特征,包括NVIDIA T4、NVIDIA 3090、Atlas 300I DUO等多种AI加速设备,并在不同场景下协同运行。这些设备承担着包括人流密度监测、人脸识别、车牌抓拍等计算机视觉任务,系统负载、资源调度与运维策略已形成稳定运行机制。
近期,该园区在安防升级过程中面临一项临时但复杂的智能分析挑战:在突发事件响应、演练预警或夜间非业务时段,需临时部署并运行多模态大模型,实现图文联合理解、行为链条分析、场景异常检测等复杂推理任务。该需求需在不增加硬件投入、不影响现有业务运行的前提下完成。
为应对这一挑战,润和软件自研的StackRUNS异构分布式推理框架成为关键解决方案。该框架具备以下核心能力:
1. 异构算力识别与建模:自动识别各设备的计算能力、显存规格与精度支持能力,为模型切片和任务分配提供实时依据;
2. 模型智能切分与并行执行:支持基于专家路由与自动切分策略,将超大模型按需划分为多个计算子任务,分布式调度到可用节点;
3. 轻量级调度与动态推理通路编排:在不干扰现有CV业务的前提下,构建独立推理通路,临时占用空闲资源执行推理任务,任务完成后自动回收;
4. 混合精度与量化模型支持:支持INT8、INT4等低精度模型快速加载,提升内存利用率与执行效率;
5. 统一通信与高效协同机制:通过通信适配层封装多协议通信接口,实现多设备间高效数据传输与协同执行。
StackRUNS多模态模型场景图
StackRUNS帮助超大模型在资源受限、基础设施异构的环境中,实现“即需即调、弹性运行、无感部署”的能力,显著提升园区对突发安防场景的智能响应水平,为大模型在城市级AI基础设施中的灵活应用提供了可复制范式。
案例二:高校运行满血版DeepSeek-MoE 671B
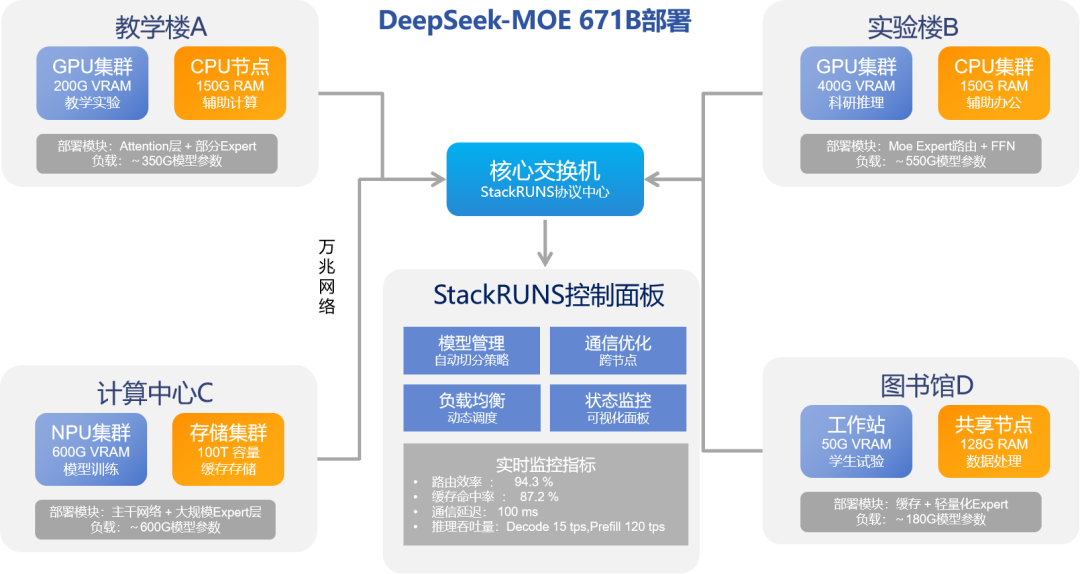
某高校在人工智能教学与科研实践中,面临运行超大规模模型的现实挑战。一方面,教学楼、实验楼与计算中心分布着多种异构计算资源,包括GPU、NPU设备及部分高性能CPU节点;另一方面,受限于经费与硬件条件,难以通过集中式部署满足超大模型推理需求。
为此,该高校引入润和软件自研的StackRUNS异构分布式推理框架,成功在现有资源基础上部署并运行了DeepSeek-MoE 671B级别的多模态大模型。
1. 通信开销高,跨设备、节点推理效率受限:传统通信架构难以适配异构环境,频繁阻塞;
2. 模型规模大、结构复杂度高:单个子模型或路由后激活路径仍需百GB级显存支撑,传统GPU、NPU单卡难以支撑模型加载与中间态存储;
3. 切片并行策略自动生成难:模型需划分为跨卡跨节点子图,兼顾通信代价、算子依赖与硬件负载能力,自动化策略生成复杂;
4. 模型运行状态监控与可视化困难:推理过程中需监控路由结果、设备负载、通信代价、缓存命中率等。
通过StackRUNS部署满血版DeepSeek示例图
借助StackRUNS,高校成功打通了异构设备之间的算力协同壁垒,实现了超大模型的低门槛部署与高效推理,广泛应用于图文语义理解、跨模态知识挖掘、学生AI实验等场景。该方案不仅显著提升了设备利用率与推理任务执行效率,也加速了人工智能专业课程与科研课题向真实算力环境的落地验证,真正实现了“在资源有限条件下,用分布式智能拼出超级算力”,为高校人工智能教学与科研提供了强有力的技术支撑。
往期回顾
